pre-amble
「Spanner のデータを Change stream, Dataflow を使って別プロジェクトにある BigQuery にデータを流してみよう」というお題をもらったのでやってみた。BigQuery 以外触ったことなかったのでまずそれぞれどんなもんだい、ってとこから始まった。
setup
- project A: Spanner, DataFlow
- project B: BigQuery
Spanner (Change stream) → Dataflow → BigQuery
Spanner
Spanner とは
何も知らないので、Cloud SQL が RDBMS なのに対して Spanner は KV store なのかな? とか思ったけど、そんなことはなく RDBMS みたいに使えて*、PostgreSQL と Google Cloud SQL の2つの SQL dialect の選択肢がある。
*公式が「Spanner provides a solid foundation for all kinds of applications with its combination of familiar relational database management system (RDBMS) features, such as ... and unique features such as strong external consistency via TrueTime and high availability via native synchronous ...」と言ってるので、 RDBMS と言い切るのも微妙な気がした。RDBMS +α って感じ?
この SO だと、「Cloud SQL で事足りるならそれで OK、それ以上のデータ量とかの要件があるなら Spanner」って言ってた↓
sample DB + backend
「Spanner はコストがえぐいから、とりあえず free instance を使うといいよ」とのことだったので見てみたところ、90日間使える free instance があった。個人的に、90日を過ぎて消し忘れても 30-day grace period の後に勝手に消してくれるのが嬉しいポイント。
Spanner free trial instances overview | Google Cloud
で、さらにすごいのがチュートリアルで勝手にデータを流してくれるバックエンド + DB がコマンド2つで用意できるところ... というのがこの辺に書いてある↓
Create a Spanner free trial instance and sample application | Google Cloud
30分もあれば上のページにある内容はとりあえず動かすところまではいける (理解はともかく)。
自分用コマンド↓
# in tab 1
gcloud auth application-default login
gcloud spanner samples backend \
finance --instance-id \
<instance-id>
# in tab 2
gcloud auth application-default login
gcloud spanner samples workload \
finance
outputs
というわけで、
- trial-instance という Spanner instance
- の中に、
finance-dbというデータベース - の中に、
Accounts,TransactionHistoryなどのテーブル
が作成された状態がここまで
Change stream
Change stream とは
個人的に、
CREATE CHANGE STREAM SingerAlbumStream FOR Singers, Albums;
という DDL で作成するものですよというのが一番わかりやすい説明かも。
公式の説明だと、
A change stream watches and streams out a Spanner database's data changes—inserts, updates, and deletes—in near real-time.
...
Spanner treats change streams as schema objects, much like tables and indexes. As such, you create, modify, and delete change streams using DDL statements, and you can view a database's change streams just like other DDL-managed schema objects.
とのことで、
- データベースへの変更を stream するモノ
- モノ = schema object → table, index と同じように扱える
というのが自分的ポイントだった。
sauce: Change streams overview | Spanner | Google Cloud
Change stream の作成
Change stream はデータベース全体に対して作成することもできるし、特定のテーブル・カラムに対して作成することもできる。今回は TransactionHistory に対してだけ作ってみたかったので (なんとなく)、↓の DDL を Spanner Studio* の中で実行した。
CREATE CHANGE STREAM TransactionStream FOR TransactionHistory
(CamelCase なのはサンプルコードに従ったから)
*Spanner Studio は Spanner に対していろいろクエリが書けるエディタで、BigQuery に慣れてれば違和感なく使えると思う。多分。
outputs
trial-instance の中に finance-db.TransactionHistory に対する change stream ができた
Dataflow の作成
作業的にはここまでと同様ボタンぽちぽちで終わるんだけど、Dataflow job の設定にあたっていろいろわからないことがあったので一番大変だった。↓の記事がめちゃ参考になった。
【Cloud Spanner】Change StreamsをBigQueryに保存して利用する
概要としては、
- Spanner change stream → BigQuery の Dataflow job を作成するには、すでにある「テンプレート」ってやつを使えばすぐできる (テンプレートを選択して Run Job をクリックするだけ)
BigQuery dataset (in other project) の作成
Dataflow job を作成してるときに destination を作ってないことに気がついたので、お題の「別プロジェクトの BigQuery」を設定した。
↓ の画像のようなフィールドなんだけど、(1) dataset 単位で job を作る (2) datasetId だけでなく project.datasetId の形式で設定できるというのがポイントだった。

(1) に関しては、change stream の最大の単位が DB なので (インスタンスではなく) よく考えたら「たしかに」ってなった。 (2) に関しては、前回の Datastream みたいに UI で裏技を使わないと別プロジェクトの BigQuery を指定できない、とかではないので安心した。
Service Agent への権限付与
ベスプラ的には service account を別途つくるべきなのだが、いったん何も指定しないで job を作成することにした。で、このときどの service agent が使われるかなんだけど、結論 Compute Engine と同じ <project number>-compute@developer.gserviceaccount.com になるっぽい (何も指定しなかったらこれになった)。
ただ、 xx-compute@... とは別に Dataflow の service agent はあるようなので、本来は Dataflow の方が使われるのか..? ほんとは作ったあとに権限をつけたので、ここらへんはちゃんと確認できてえいない。

Service agents | IAM Documentation | Google Cloud
何はともあれ principal がわかったので、別プロジェクトにいって <project number>-compute@developer.gserviceaccount.com に権限をつけにいった。Dataflow Service Agent の権限を見ると、bigquery.capacityCommitments.* など BigQuery Data Editor にない権限もついているので今回は BigQuery Admin をつけた。Data Editor にない権限が今回の job において使われるのかは未確認なので、ほんとは Data Editor でもよかったのかも? BigQuery Admin には bigquery.jobs.* がすでについているので、 BigQuery Job User はつけなかった。
「まじか」ってなったところ
(1) Dataflow job には pause/resume がない
ストリームなのでそれはそう案件なのかもだけど、 Dataflow job は一度止めると「再開」というのがない。代わりに、止めたジョブをクローンすることで再開的な挙動にさせることができるけど、停止〜再開してた間のデータがどうなるのかはよくわかってない
(2) 同じ名前の実行中の Dataflow job は複数作成できない
1 のところで、止めたあとに job をクローンしようとしたんだけど、名前をそのままにしておいたらエラーになった。ただ、job は止まるのに時間がちょっとかかる (体感10分くらい?) ので、止まるまで待てば同じ名前の job は作成できる。
outputs
- Dataflow job
- IAM binding for Compute Engine default service account x BIgQuery Admin in the other project
これで Spanner → Change stream → Dataflow job → Bigquery ができて、 BigQuery にデータ入ったことも確認できた。

調べもの
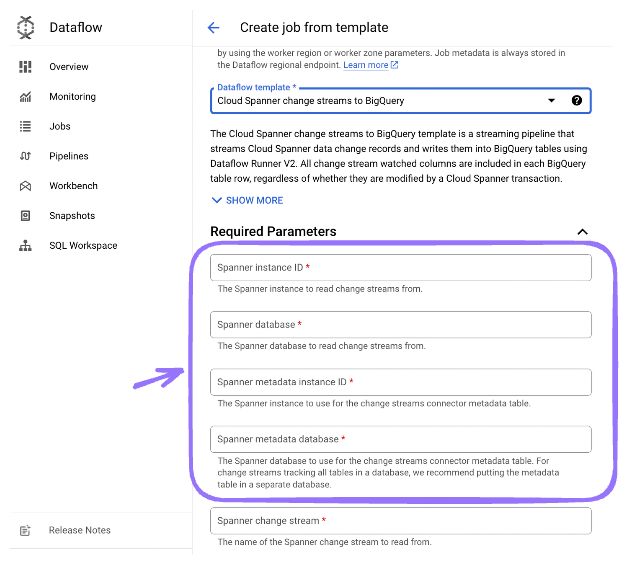
Dataflow job > "metadata instance ID" "metadata database" とは??
いかんせん Dataflow のジョブは設定項目があって、必須項目の中だけでも結構 ??? になった
Create and manage change streams | Spanner | Google Cloud
ここに書いてあって、 change stream の internal state を管理するためのデータを metadata instance/database が必要。これは実際のデータが入ってる instance/database と同じでもいいけど、↓の理由から分けることがおおすすめ
- 実データの方を readonly アクセスにできる
- DB 全体を watch する change stream (
FOR ALL) の場合、change stream のメタデータへの変更か実データへの変更かを気にしなくていい
Change stream: exclude TTL based deletes
Spanner のデータには "TTL" (time-to-live) を設定できて、GCS の lifecycle policy のように一定期間後自動的にデータが削除されるようにできる。で、 Change stream でこの TTL 起因の delete を watch しないように設定できる。